
Machine Learning - Reinforcement Learning
In this series I am going to be talking about machine learning and artificial intelligence. I will be covering three main branches of machine learning: supervised learning, unsupervised learning, and reinforcement learning. In this post I'll be talking about reinforcement learning, as it is one of the ones I find the most fun.
If you haven't done already, and need a primer, go and read my introduction to machine learning that I wrote previously: What is Machine Learning / Artificial Intelligence?
So, here we go. Who has one of these at home?

- No, not an Ewok... it is in fact a dog, Violet, my pug/bichon cross. If you have a dog or are a parent, you probably have already come across reinforcement learning. It is the act of learning via a reward. Reinforcing good behaviour with a treat. Perhaps discouraging unwanted behaviour via a punishment.
- You tell your dog to sit. It has no idea what the word 'sit' means. It looks at you. You give it a hint, maybe, holding a treat above it's head so it sits down to look up. And you give it the treat. You repeat this over and over. And the dog learns to associate the command 'sit' with the desired outcome.
- Reinforcement learning in computers is pretty much exactly the same. It is an iterative process by which an algorithm 'learns' desired behaviour by way of being given a 'reward'.
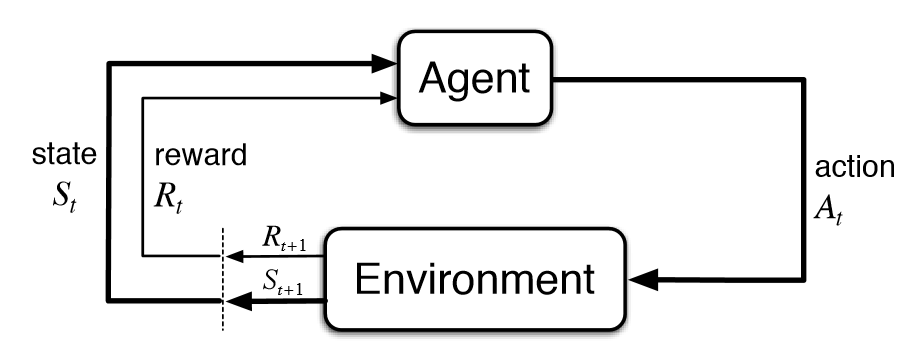
- This process is shown above as a state diagram. We have an agent (the dog), that performs an action (sits), in an environment (your house), which results in a new state (a sitting dog) and a reward (tasty treat).
- What is so great about reinforcement learning is that you don't describe
- how
- the result should be achieved, just reward the desired outcome. ie, you don't tell your dog to bend it's rear legs to sit its backside on the ground. You just reward it when it sits down.
- Let's move away from pets, and show this in the context of a computer learning to play a simple game:
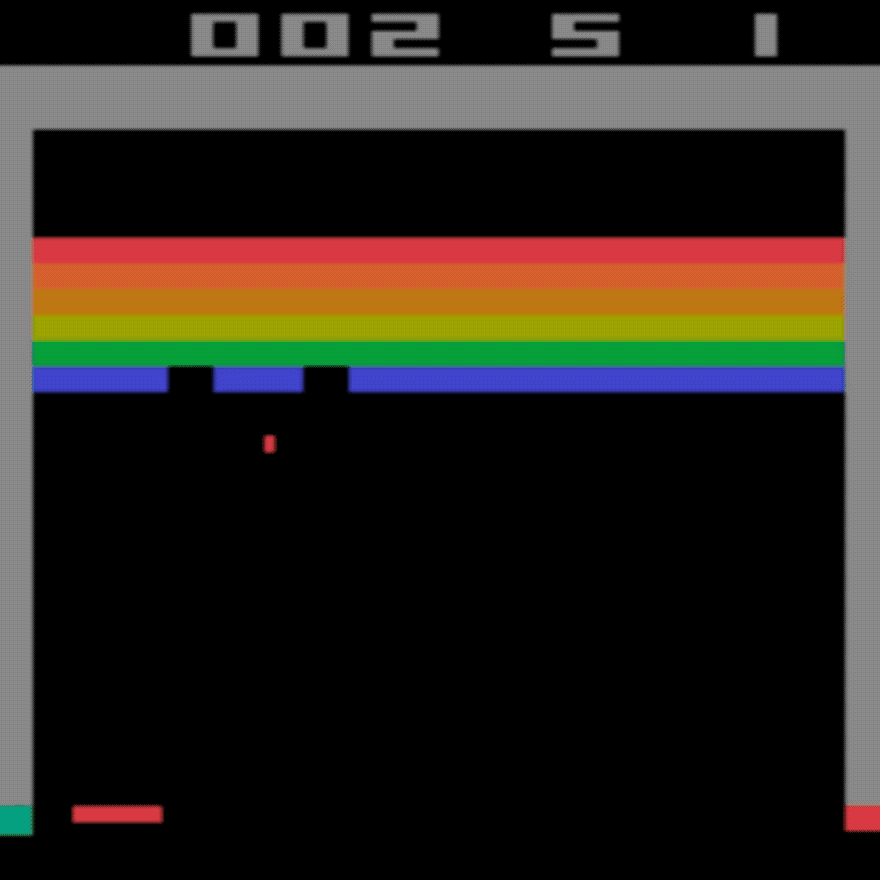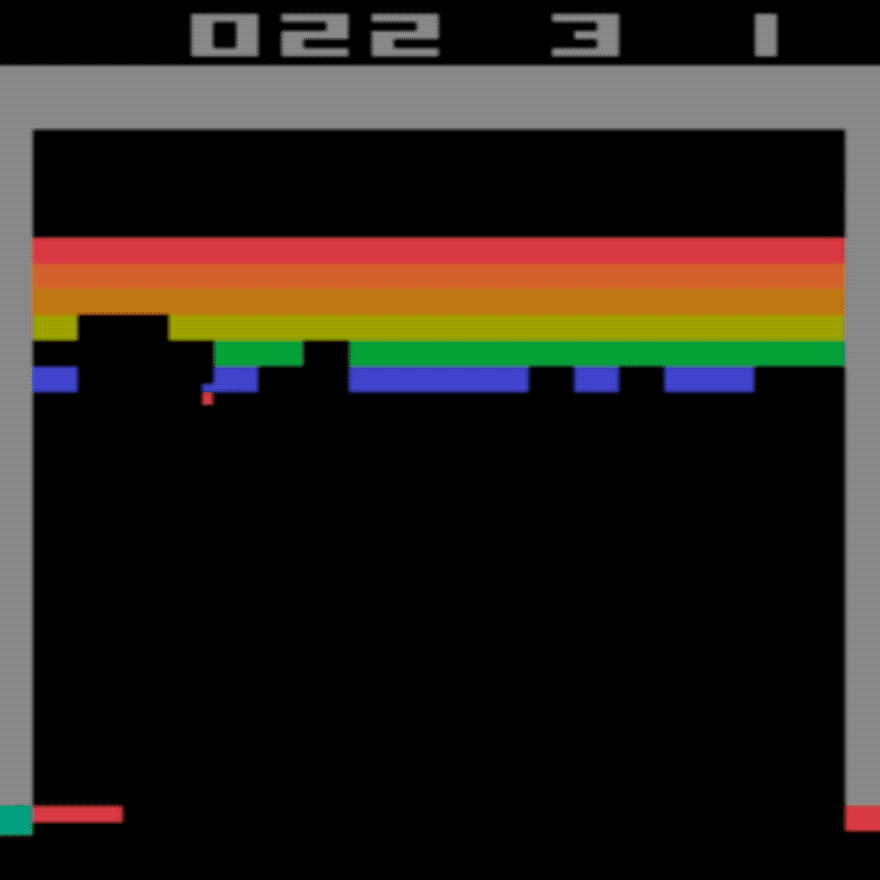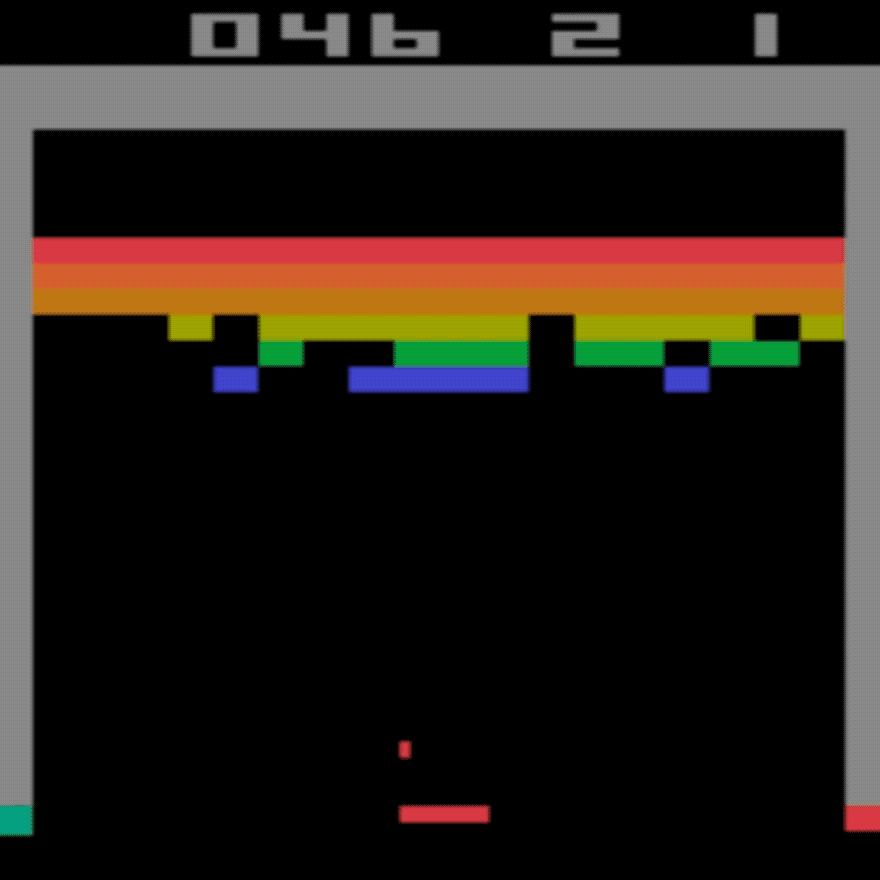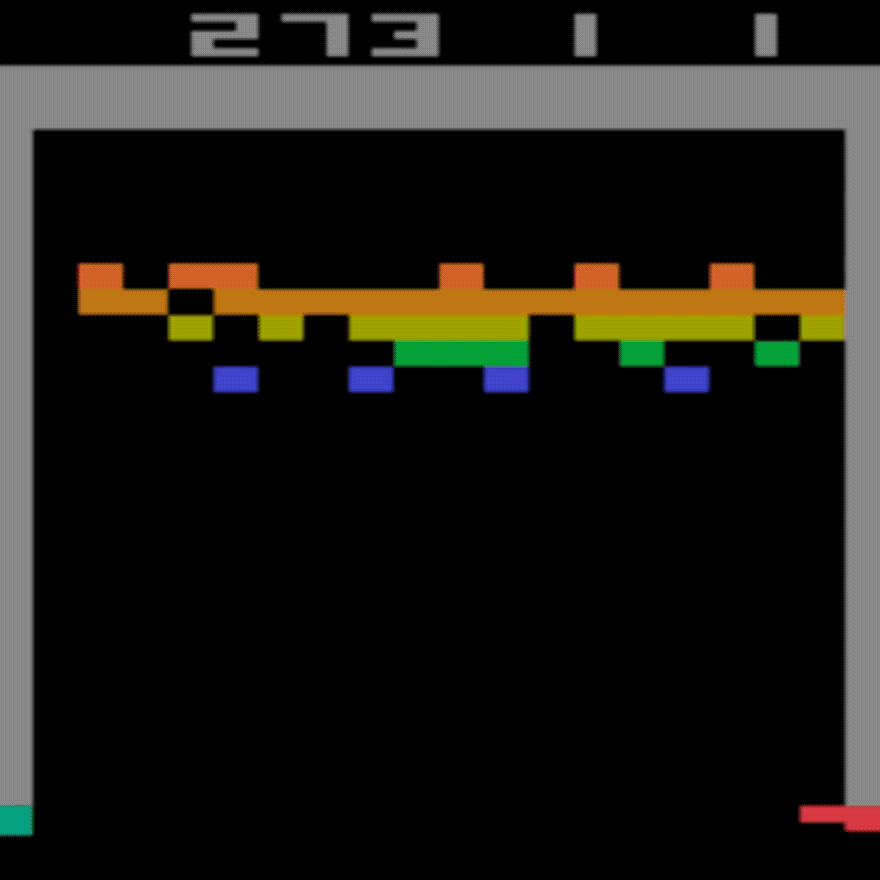
- Do you remember the Atari game "Breakout"? In the game you control a small horizontal "paddle" at the bottom of the screen. You have a joystick or controller and can press "left" or "right" to move the paddle. A ball bounces around the screen and your job is to stop the ball falling out the bottom of the screen. A bit like pinball. You have to bounce it off the coloured blocks and the top and try to destroy them all. You get a score for each block you destroy.
- We can use reinforcement learning to teach a computer how to play this game. We have two possible
- actions
- left and right
,
we have a
state
which is the grid of coloured pixels that make up the screen, and we have a
reward
, the high score. So the job of the algorithm is to look at the pixels (the image on the screen), move the paddle left or right, and observe the score as a reward.
At first the algorithm will do very badly. It has no idea what it is doing (just like a human player for the first few seconds playing). IT will randomly move the paddle left and right. It has no idea what the coloured pixels on the screen represent, or even what the ball is.
But with each successive iteration it learns a little bit. In most cases RL algorithms use a neural network to process the images. I'll describe these in a later post, but they are effectively a model of a human brain and the neurons in it.
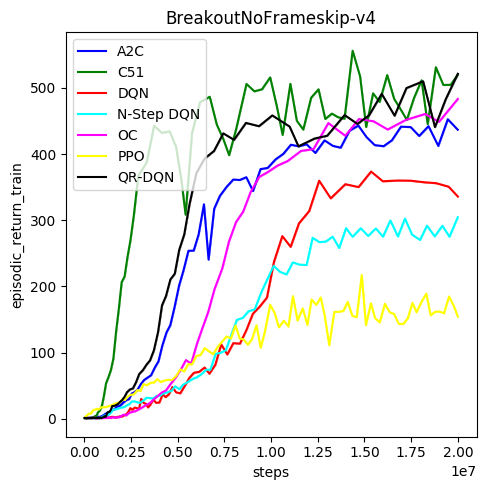
Above is a graph showing the score after each game played of breakout for various RL algorithms. Each coloured line is a different algorithm, and each one learns in a slightly different way. The axis along the bottom is in millions of steps, so this graph covers two million steps (iterations) in total. As you can see, at the start, they all get a pretty low score. Then over time, they learn. Some faster than others. For example, PPO doesn't get a very high score overall (around 150). Others, e.g. C51 got scores over 500.
At the end, the algorithm has learned that it needs to position the paddle to where the ball is heading in order to bounce the ball back up to the blocks. It has learned to play the game.
What else can we use reinforcement learning algorithms for?